

Why Anemic Domain Model can be Harmful
Anemic Domain Model is a common approach in software development that many folks don’t even know they are using it




Photo by Michael Geiger on Unsplash
What is the Anemic Domain Model
It is a Model which separates data and operations working with them from each other. Most of the time, your domain consists of two separated classes. One is the entity, which is holding data, the other is the stateless service, which operates with an entity.
The entity is usually represented with public properties. Setters and getters. A typical example of Entity Framework entity in the .NET application can look like this:
public class Movie
{
public string Title { get; set; }
public string Description { get; set; }
public List<Actor> Actors { get; set; } = new List<Actor>();
}
Stateless service, as the name suggests, is represented with stateless class, which means that it contains methods only and such methods should operate only with a related entity. Its Stateless Service can look like this:
public class MovieService
{
public void Create(string title, string decription, List<Actor> actors) { ... }
public void AddActor(Movie movie, Actor actor){ ... }
public List<Actor> GetMainActors(Movie movie) { ... }
}
You may use more than one service class to operate with an entity. This example serves to demonstrate the idea behind the Anemic Domain Model.
Why is the Anemic Domain Model harmful
One could say that the Anemic Domain Model is not going along with Object-Oriented Design. The separation of logic into other classes is just not correct in the OOD approach. But it is not the primary reason why the Anemic Domain Model is harmful. Having a pure OOD is not the goal in and of itself. We need to consider more fundamental reasons. There are three of them.
First is discoverability, meaning easy finding out what we could do with the object just by using IntelliSense. Lack of discoverability may lead to duplicating already existing code.
This flows us to the second reason and that is duplication. When you don’t keep methods near to data, it is hard to say where exactly they are located. The developer forfeits the idea to write their own implementation of those methods, which results in duplicating some or all already existing logic.
The third is the lack of encapsulation and this one is the worst. The first two are more easily avoided by applying codebase standards. This one, however, always has a harmful effect on your project. It is precisely the lack of encapsulation that ruins most code bases employing Anemic Domain Models.
What is encapsulation
There are a few definitions of what encapsulation is. Some believe that encapsulation is information hiding. That is when you make some of the class members private and therefore hide them from the client code. While this is one of the means of achieving encapsulation, the information hiding is not the encapsulation per see.
Another definition you can counter is, that encapsulation means bundling data and operations together. While this is also a way to achieve encapsulation in object-oriented programming languages, it is not the same as encapsulation either.
Encapsulation is an act of protecting the data integrity
This is usually done by preventing clients of a class from setting the internal data into an invalid or inconsistent state. And that is where tools such as information hiding, and bundling data and operations together come helpful.
Information hiding helps you remove the internals from the eyes of its clients, so there is less risk of corrupting it.
Bundling of data and operations provides you with the one entry point for all actions you do in this class. This way you can perform all required validations and integrity checks before modifying the internal state.
As you can see, these two techniques are related to encapsulation in the sense to achieve it, they themselves are not the end goal.
You can also think of encapsulation in terms of invariants. Each class has its own set of invariants, conditions that you can always rely upon to be true. It is your responsibility as a software developer to make sure that those invariants are valid during the execution of the program.
Why is so important to maintain the encapsulation
It is all about complexity. The more complex the codebase becomes, the harder is to work with it, which ultimately results in the decreasing speed of development, increasing the number of bugs, and damaging the ability to respond to business needs.
Just imagine that your code doesn’t guide you through what is and what is not allowed to do with it, and you must double-check repeatedly. It brings a lot of mental burden in the process of programming. You cannot trust yourself to do always the right thing and the best way to do so is by maintaining proper encapsulation so that your codebase doesn’t even provide an option for you to do anything incorrectly.
How to maintain the encapsulation with Anemic Domain Model
An Anemic Domain Model always means a lack of encapsulation. You must expose invariants to external worlds. There doesn’t exist a proper way to make a former set of classes to avoid it.
The classes of data end up having no restrictions on how you can change them and therefore the responsibility to maintain the invariants shifts to the classes of operations, which is a very dangerous situation because you have to remember to keep all invariants intact each time you modify a class with data.
Why we are even using it
Because it is intuitive for developers, especially the one who comes from a data background. Therefore, it is easy to implement, which can be beneficial sometimes.
But what if I want to maintain the encapsulation
Then you should go tame a beast named Domain-Driven Design. DDD guides you on how to design your entities differently than you are used to. But this doesn’t mean that the Anemic Domain Model is always the wrong approach. Look at this image below.
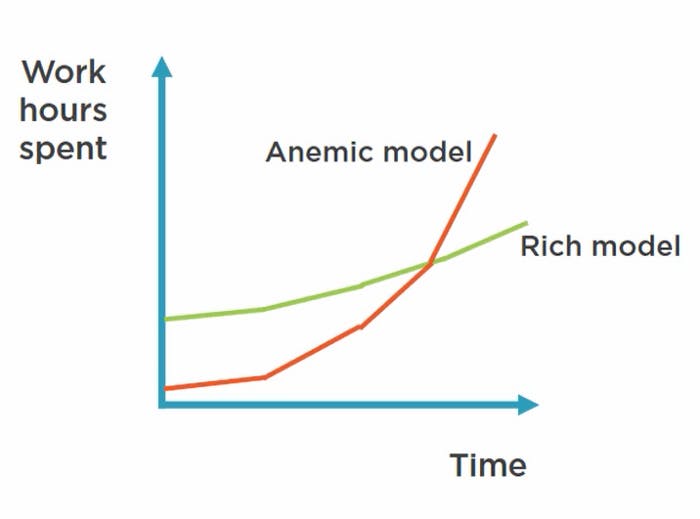 Source of the image is pluralsight.com course by Vladimir Khorikov — Refactoring from Anemic Domain Model Towards a Rich One.
Source of the image is pluralsight.com course by Vladimir Khorikov — Refactoring from Anemic Domain Model Towards a Rich One.
Graph narrates about development progress measured by spent work hours. As you can see, Anemic Domain Model projects always take off quickly, leading to an increase in maintenance costs in the future. In cases where you know that project is not going large or the project will not be developed more often, the Anemic Domain Model is just fine to pick and could also be the best choice.
However, if you find yourself at the beginning of the development of enterprise applications, a rich Domain Model by DDD is the preferable and more recommended choice.
Is it always per project decision
The decision of whether to deploy the Anemic Domain Model is local to a particular bounded context in your system. In some bounded context, you might want to implement an Anemic Domain Model, in others go with the rich one. Bounded context is separate from each other and you can deploy them by different strategies in each of them.
Conclusion
The article is heavily inspired by, in my humble opinion, one of the best Domain-Driven Design evangelists, .NET Architects and Pluralsight authors, Vladimir Khorikov, and one of his courses “Refactoring from Anemic Domain Model Towards a Rich One”. If you are hungry for more information, you can easily pick up where the article left off, and that is in the fourth module of the already mentioned course.
